반응형
# Normalization
- 클러스터링 전에 변수들의 scale을 유사한 수준으로 변경
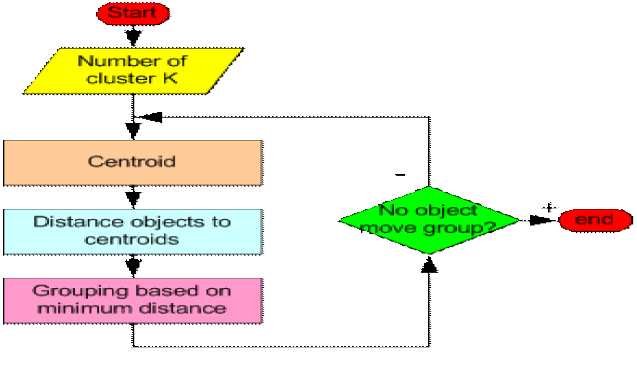
# K-means : 군집분석 방법
- 주어진 데이터를 특정 성질에 기초해서 k개 묶음으로 나누는 대표적 방법
- 공간상의 점들을 서로 가까운 점들끼리 묶어서 몇 개의 군으로 나누는 군집화기법
- 군집화할 개수인 K를 변경해가면서 결과 확인
- 결과분석
. 실루엣 기법은 군집 내 응집도와 분리도를 계산
. 실루엣 계수가 1에 가까울수록 잘 나누어짐
. 실루엣 계수가 큰 값을 나타내는 k(그룹수)를 선택하여 k-means 재수행
대표사진 삭제
사진 설명을 입력하세요.
# K-means clustering algorithm의 문제점
- 초기 조건(중심점 위치, 집단 수)에 따라 결과가 상이할 수 있음
- 분별력 문제 : 데이터, 가중치가 모두 동일
- 클러스터링이 원의 형태이면 경우에 따라 애매한 데이터 발생
# K-means 활용사례
- Data Mining 에서 데이터 분류 및 군집 알고리즘으로 활용
- 시장과 고객 분석, 패턴인식, 공간데이터 분석, Text Mining 등
- 최근에는 패턴인식, 음성인식의 기본 알고리즘으로 활용
- 데이터가 불규칙하고 내부 특징이 알려지지 않은 분류 초기 단계에 적합
# Spectral Clustering
- 변수간의 거리에 따라 군집이 형성되는 k-means와 달리
평균과 가까운 곳에 모여있는 군집과 그 이외의 군집으로 나누어짐
반응형
'① IT 스타트 (IT Competence) > IT관련 스크랩' 카테고리의 다른 글
| Wi-Fi 6, 802.11ax, HEW (0) | 2021.08.13 |
|---|---|
| 코드사인, 코드서명 (0) | 2021.08.13 |
| [데이터분석] 회귀분석(Regression Analysis) (0) | 2021.08.13 |
| [모니터] BenQ GW2780 구입 (0) | 2021.08.12 |
| [리눅스] Ubuntu vs CentOS (0) | 2021.08.11 |

