반응형
# 순위구하기
방법1) rank() 함수를 이용
# Help로 rank 함수 사용법 확인
Help on function rank in module pandas.core.generic:
rank(self: 'FrameOrSeries', axis=0, method: 'str' = 'average', numeric_only: 'bool_t | None' = None, na_option: 'str' = 'keep', ascending: 'bool_t' = True, pct: 'bool_t' = False) -> 'FrameOrSeries'
Compute numerical data ranks (1 through n) along axis.
By default, equal values are assigned a rank that is the average of the
ranks of those values.
Parameters
----------
axis : {0 or 'index', 1 or 'columns'}, default 0
Index to direct ranking.
method : {'average', 'min', 'max', 'first', 'dense'}, default 'average'
How to rank the group of records that have the same value (i.e. ties):
* average: average rank of the group
* min: lowest rank in the group
* max: highest rank in the group
* first: ranks assigned in order they appear in the array
* dense: like 'min', but rank always increases by 1 between groups.
numeric_only : bool, optional
For DataFrame objects, rank only numeric columns if set to True.
na_option : {'keep', 'top', 'bottom'}, default 'keep'
How to rank NaN values:
* keep: assign NaN rank to NaN values
* top: assign lowest rank to NaN values
* bottom: assign highest rank to NaN values
ascending : bool, default True
Whether or not the elements should be ranked in ascending order.
pct : bool, default False
Whether or not to display the returned rankings in percentile
form.
Returns
-------
same type as caller
Return a Series or DataFrame with data ranks as values.
See Also
--------
core.groupby.GroupBy.rank : Rank of values within each group.
Examples
--------
>>> df = pd.DataFrame(data={'Animal': ['cat', 'penguin', 'dog',
... 'spider', 'snake'],
... 'Number_legs': [4, 2, 4, 8, np.nan]})
>>> df
Animal Number_legs
0 cat 4.0
1 penguin 2.0
2 dog 4.0
3 spider 8.0
4 snake NaN
The following example shows how the method behaves with the above
parameters:
* default_rank: this is the default behaviour obtained without using
any parameter.
* max_rank: setting ``method = 'max'`` the records that have the
same values are ranked using the highest rank (e.g.: since 'cat'
and 'dog' are both in the 2nd and 3rd position, rank 3 is assigned.)
* NA_bottom: choosing ``na_option = 'bottom'``, if there are records
with NaN values they are placed at the bottom of the ranking.
* pct_rank: when setting ``pct = True``, the ranking is expressed as
percentile rank.
>>> df['default_rank'] = df['Number_legs'].rank()
>>> df['max_rank'] = df['Number_legs'].rank(method='max')
>>> df['NA_bottom'] = df['Number_legs'].rank(na_option='bottom')
>>> df['pct_rank'] = df['Number_legs'].rank(pct=True)
>>> df
Animal Number_legs default_rank max_rank NA_bottom pct_rank
0 cat 4.0 2.5 3.0 2.5 0.625
1 penguin 2.0 1.0 1.0 1.0 0.250
2 dog 4.0 2.5 3.0 2.5 0.625
3 spider 8.0 4.0 4.0 4.0 1.000
4 snake NaN NaN NaN 5.0 NaN
None
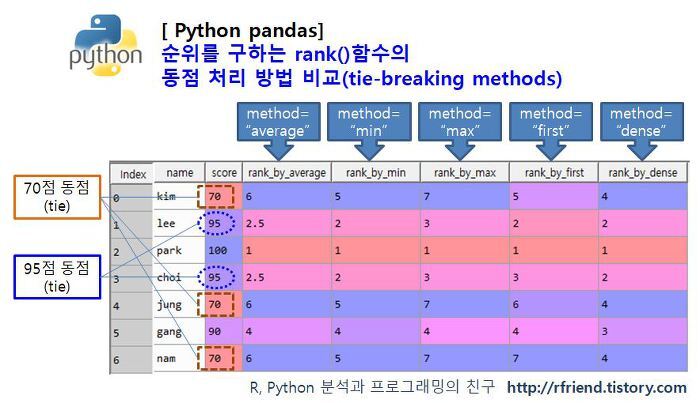
df['rank_average'] = df['score'].rank(method='average', ascending=False)
- 동점인 경우 등수의 평균값을 가짐, 디폴트 값
df['rank_min'] = df['score'].rank(method='min', ascending=False)
- 동점인 경우 가장 상위 등수를 가짐
df['rank_max'] = df['score'].rank(method='max', ascending=False)
- 동점인 경우 가장 하위 등수를 가짐
df['rank_first'] = df['score'].rank(method='first', ascending=False)
- 동점인 경우 먼저 읽은 데이터가 상위등수를 가짐
df['rank_dense'] = df['score'].rank(method='dense', ascending=False)
- 동점의 개수와 상관없이 다음 차수가 + 1된 등수를 가짐
방법2) sort_values() 함수를 이용
파라미터 ascending = False : 내림차순
data_new = data['MEDV'].sort_values(ascending = False)
data_new.head(30)
30번째 값으로 1~29번째 값을 변경하기
data_new.iloc[0:28] = 41.7
print(data_new.iloc[0:28])
# help 로 sort_values 사용법 확인
print(help(pd.DataFrame.sort_values))
Help on function sort_values in module pandas.core.frame:
sort_values(self, by, axis: 'Axis' = 0, ascending=True, inplace: 'bool' = False, kind: 'str' = 'quicksort', na_position: 'str' = 'last', ignore_index: 'bool' = False, key: 'ValueKeyFunc' = None)
Sort by the values along either axis.
Parameters
----------
by : str or list of str
Name or list of names to sort by.
- if `axis` is 0 or `'index'` then `by` may contain index
levels and/or column labels.
- if `axis` is 1 or `'columns'` then `by` may contain column
levels and/or index labels.
axis : {0 or 'index', 1 or 'columns'}, default 0
Axis to be sorted.
ascending : bool or list of bool, default True
Sort ascending vs. descending. Specify list for multiple sort
orders. If this is a list of bools, must match the length of
the by.
inplace : bool, default False
If True, perform operation in-place.
kind : {'quicksort', 'mergesort', 'heapsort', 'stable'}, default 'quicksort'
Choice of sorting algorithm. See also :func:`numpy.sort` for more
information. `mergesort` and `stable` are the only stable algorithms. For
DataFrames, this option is only applied when sorting on a single
column or label.
na_position : {'first', 'last'}, default 'last'
Puts NaNs at the beginning if `first`; `last` puts NaNs at the
end.
ignore_index : bool, default False
If True, the resulting axis will be labeled 0, 1, …, n - 1.
.. versionadded:: 1.0.0
key : callable, optional
Apply the key function to the values
before sorting. This is similar to the `key` argument in the
builtin :meth:`sorted` function, with the notable difference that
this `key` function should be *vectorized*. It should expect a
``Series`` and return a Series with the same shape as the input.
It will be applied to each column in `by` independently.
.. versionadded:: 1.1.0
Returns
-------
DataFrame or None
DataFrame with sorted values or None if ``inplace=True``.
See Also
--------
DataFrame.sort_index : Sort a DataFrame by the index.
Series.sort_values : Similar method for a Series.
Examples
--------
>>> df = pd.DataFrame({
... 'col1': ['A', 'A', 'B', np.nan, 'D', 'C'],
... 'col2': [2, 1, 9, 8, 7, 4],
... 'col3': [0, 1, 9, 4, 2, 3],
... 'col4': ['a', 'B', 'c', 'D', 'e', 'F']
... })
>>> df
col1 col2 col3 col4
0 A 2 0 a
1 A 1 1 B
2 B 9 9 c
3 NaN 8 4 D
4 D 7 2 e
5 C 4 3 F
Sort by col1
>>> df.sort_values(by=['col1'])
col1 col2 col3 col4
0 A 2 0 a
1 A 1 1 B
2 B 9 9 c
5 C 4 3 F
4 D 7 2 e
3 NaN 8 4 D
Sort by multiple columns
>>> df.sort_values(by=['col1', 'col2'])
col1 col2 col3 col4
1 A 1 1 B
0 A 2 0 a
2 B 9 9 c
5 C 4 3 F
4 D 7 2 e
3 NaN 8 4 D
Sort Descending
>>> df.sort_values(by='col1', ascending=False)
col1 col2 col3 col4
4 D 7 2 e
5 C 4 3 F
2 B 9 9 c
0 A 2 0 a
1 A 1 1 B
3 NaN 8 4 D
Putting NAs first
>>> df.sort_values(by='col1', ascending=False, na_position='first')
col1 col2 col3 col4
3 NaN 8 4 D
4 D 7 2 e
5 C 4 3 F
2 B 9 9 c
0 A 2 0 a
1 A 1 1 B
Sorting with a key function
>>> df.sort_values(by='col4', key=lambda col: col.str.lower())
col1 col2 col3 col4
0 A 2 0 a
1 A 1 1 B
2 B 9 9 c
3 NaN 8 4 D
4 D 7 2 e
5 C 4 3 F
Natural sort with the key argument,
using the `natsort <https://github.com/SethMMorton/natsort>` package.
>>> df = pd.DataFrame({
... "time": ['0hr', '128hr', '72hr', '48hr', '96hr'],
... "value": [10, 20, 30, 40, 50]
... })
>>> df
time value
0 0hr 10
1 128hr 20
2 72hr 30
3 48hr 40
4 96hr 50
>>> from natsort import index_natsorted
>>> df.sort_values(
... by="time",
... key=lambda x: np.argsort(index_natsorted(df["time"]))
... )
time value
0 0hr 10
3 48hr 40
2 72hr 30
4 96hr 50
1 128hr 20
None반응형
'독서' 카테고리의 다른 글
| 오름차순/내림차순 (0) | 2022.06.05 |
|---|---|
| 그룹별 집계, 요약하기 (0) | 2022.06.03 |
| 이클립스 Dynamic Web Project에 WebContent 없음 (폴더 구조 수정방법) (0) | 2022.06.02 |
| 파이썬 패키지명을 찾는 방법 (0) | 2022.06.02 |
| 범주형을 수치형으로.. 데이터 타입 변경 (0) | 2022.05.20 |
